Model Settings Screen (Details)
The Model Settings screen (Details) allows you to specify more advanced settings when creating a prediction model.
Create a prediction model
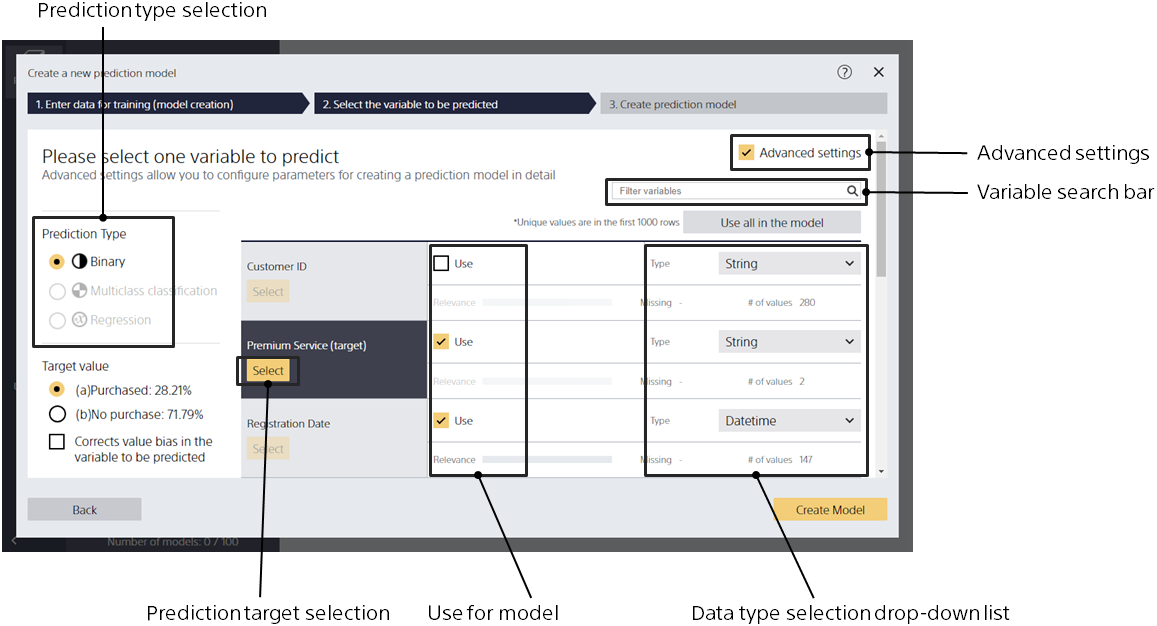
Step 1. Click the button to select the variable you want to predict.
If you cannot click [Select], you cannot create a prediction model that predicts the variable.
Step 2. Click the [Create Model] button.
Specify the prediction type
Step 1. Click the button to select the variable you want to predict.
Step 2. From Prediction Type, specify the prediction type.
The following rules automatically select a prediction type, with some exceptions: The rule uses the number of unique values (the number of possible string types), which is counted by reading the first 1000 rows of the prediction model creation (training) data.
- If the data type of the variable to be predicted is a string
- If the number of unique values in the item is 2, binary classification is applied.
- If the number of unique values is greater than or equal to 3 and less than or equal to 200, multiclass classification is applied.
- If the number of unique values is greater than 200, Easy Predictive Analytics does not support multiclass classification. Change the number of unique values to 200 or less by modifying or processing the data.
- If the data type of the variable to be predicted is numeric
- If the number of unique values in the item is 2, binary classification is applied.
- If the number of unique values is greater than or equal to 3 and less than or equal to 200, you can choose between multiclass classification and regression.
- If the number of unique values is greater than 200, it is regression.
- If binary classification is selected and the variable you want to predict after 1000 line contains another value, the learning fails prematurely and ends. When multiclass classification is selected and the number of unique values to be predicted for processing including data after 1000 line exceeds 200, the learning fails and ends prematurely.
Change the variables used as input for the model
Step 1. Check the [Use for model] button only for variables that you want to use as input.
Variables with too many unique values often have a negative impact on learning (over-fitting and poor predictive accuracy), so they are unchecked by default. If there are too many variables, type text in the variable search box to narrow the variables that appear in the variable list.
Specify target values in binary classification
Step 1. From Target Value, select the value you want to predict.
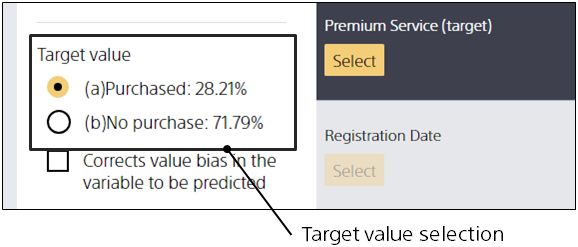
You can select and change target values by selecting Binary Classification as the prediction type. Please check the value you want to predict. In the evaluation after learning, an evaluation graph or similar is generated centering on the value that is checked.
Check the relevance with the variables you want to predict
On the Model Settings screen (Details), relevance scores can be checked only for data types that are numeric or string. The relevance score visualizes how much of a trend or correlation is found by comparing the variable to predict and another variable, and the higher the score, the greater the correlation.
For more information on how to use the relevance score, see Page about the Relevance Score in Tips.
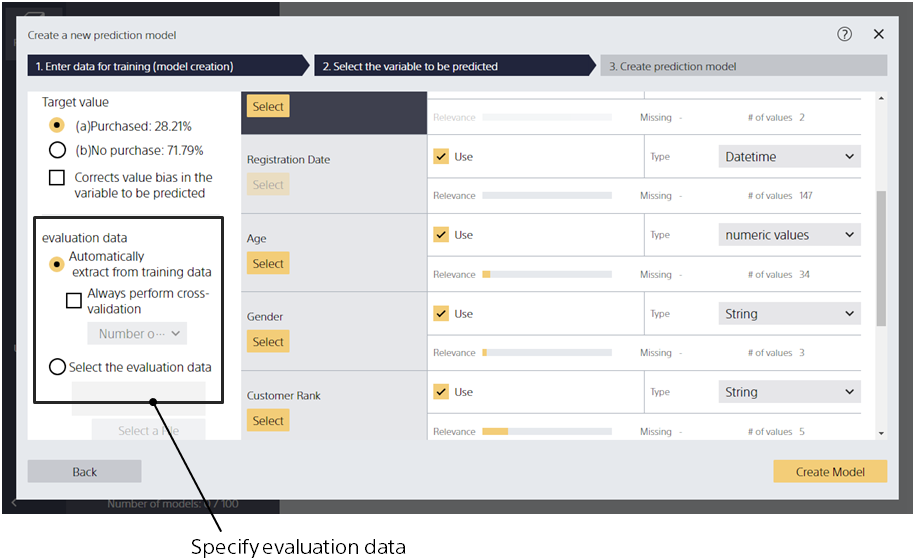
Specify the data for evaluation
Step 1. In the evaluation data specification area, select [Set another file].
Step 2. Click the [Select a File] button and specify the file on the subsequent screen.
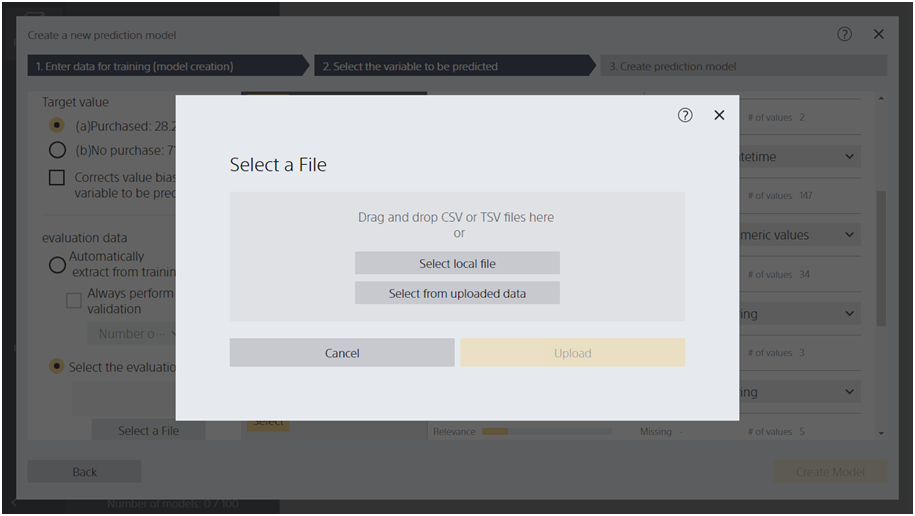
In this case, all prediction model creation (training) data is used for learning and the specified evaluation data is used for evaluation. All variables in the evaluation data and the prediction model creation (training) data must match. Otherwise, the learning and evaluation process will fail.
Specifying cross-validation as the evaluation method
Step 1. In the evaluation data specification area, check [Cross-validation].
Step 2. In the evaluation data specification area, select the number of divisions from the pull-down.
If no evaluation data is specified and the number of rows is greater than 500, Easy Predictive Analytics divides the data into 9:1, uses 90% of the data for learning, and uses 10% of the data for evaluation. If no evaluation data is specified and the number of rows is less than or equal to 500, a two-part cross-validation is performed. (The data is divided into two parts, which are used for prediction model creation (training) data and evaluation data respectively, and two patterns of learning and evaluation are performed to calculate evaluation values.)
By checking [Cross-validation], you can always perform cross-validation regardless of the data count. You can specify the number of divisions by selecting from the pull-down.
Using Data Join to Create Prediction Models
The data join feature is not available in the current version.
Rebalance in the variables you want to predict
This option can only be specified for binary or multiclass classification. When this option is enabled, the model is trained to predict the values of the variables you want to predict, especially those that occur less frequently. This option may reduce the accuracy of the classification. Also, this option may not improve prediction accuracy for data with fewer occurrences.